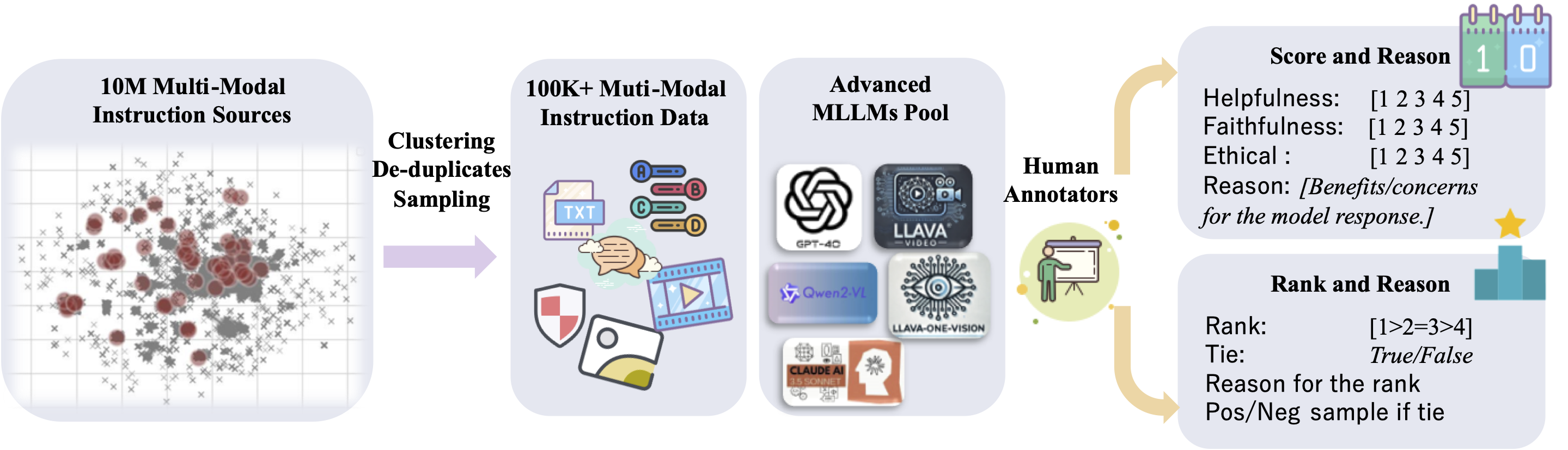
(1) Data Collection and Cleaning: Starting with 10 million instruction samples, we cluster data based on image similarity, and uniformly sample across diverse categories. This results in a diverse dataset covering image-based Q&A and video Q&A formats. (2) Response Generation: We leverage state-of-the-art models, including GPT-4o and Qwen2-VL-72B, to generate responses. (3) Human Annotation: We conduct comprehensive manual annotation across nine categories, including scoring, ranking, and textual explanations, ensuring fine-grained evaluation.
Re-Sampling results from the clustering process. Due to the large total number of samples, the clustered and deduplicated results contain a rich diversity of categories. Selected samples include topics such as mathematics, daily life, natural scenes, medicine, electronic technology, and OCR scenarios, showcasing a variety of problem-image pairs. The 2D features are obtained via UMAP dimensionality reduction.
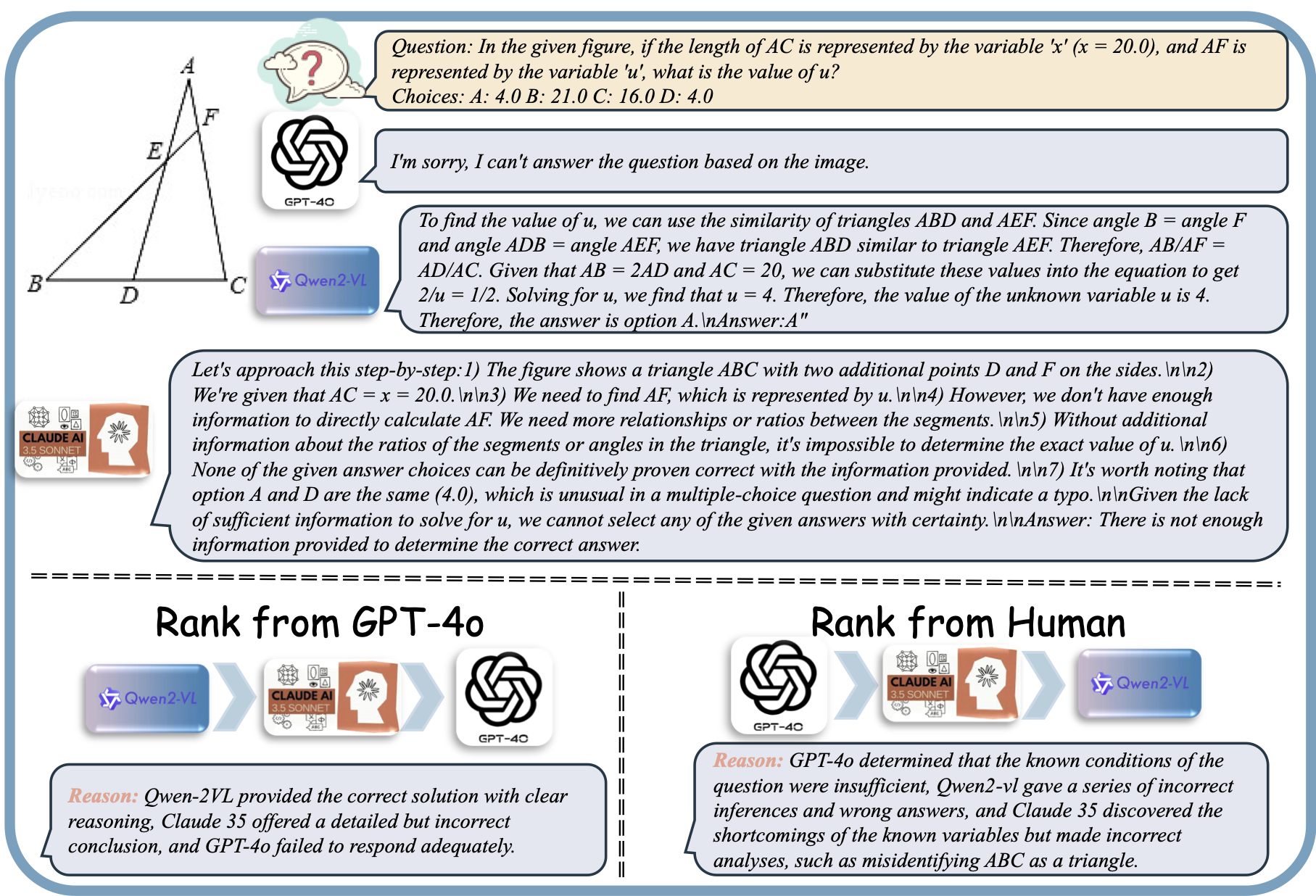

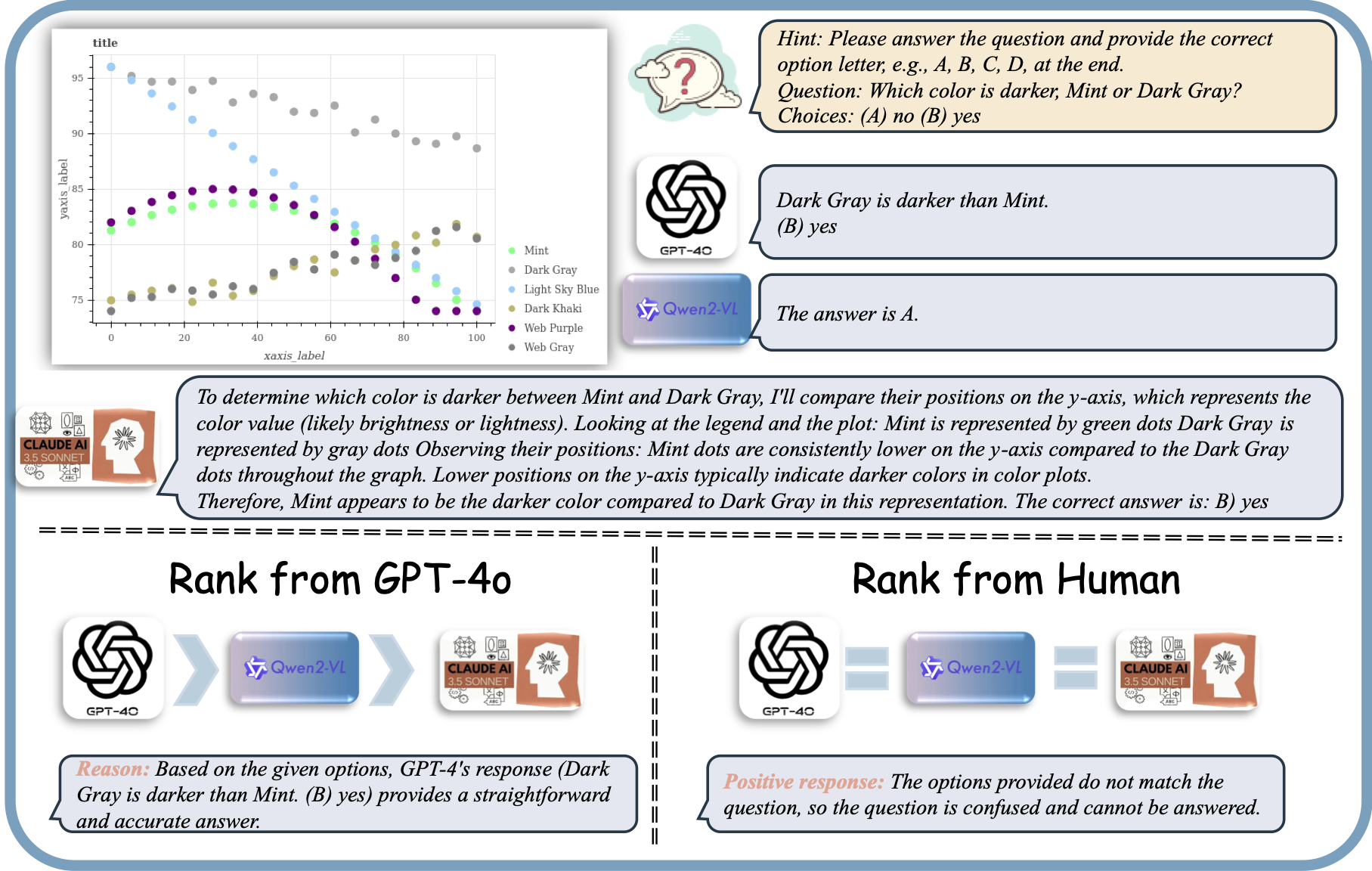


Illustration of the multi-task reward model training process. The process begins with a user query and corresponding model responses, which are ranked and annotated by humans. Human annotations are expanded using GPT-4o to provide enhanced rationales. The reward model is trained with two objectives: (1) Learning to Provide Critique, where the model learns to provide detailed critiques and evaluations for model responses, and (2) Learning Scoring, where the model learns to assign scores based on the model response and critique. The integration of these tasks ensures a robust evaluation framework for improving model outputs.
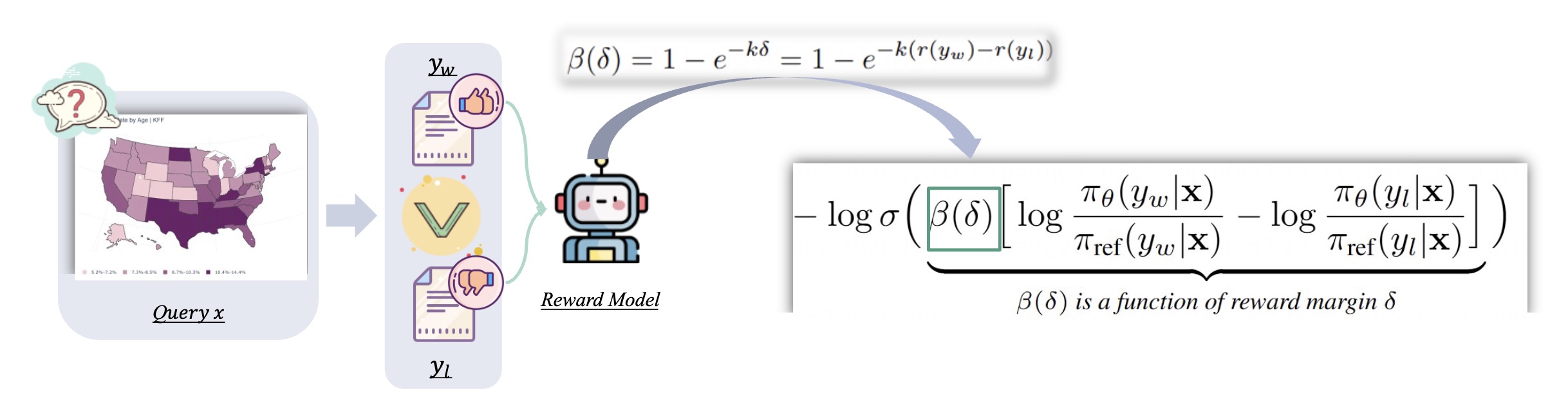
Overview of the MM-DPO framework The dynamic reward scaling mechanism adjusts the update strength based on the reward margin, improving optimization stability and robustness.

Performance comparison across metrics and methods on MM-RLHF-RewardBench. MM-RLHF-Reward (w/o. Task 1) represents training the LLaVA-OV-7B model to score pair-wise samples while excluding Task 1. MM-RLHF-Reward (w/o. enhanced annotations) involves learning human-provided annotations, followed by scoring. MM-RLHF-Reward (inference w. GT annotation) uses ground truth annotations during inference.
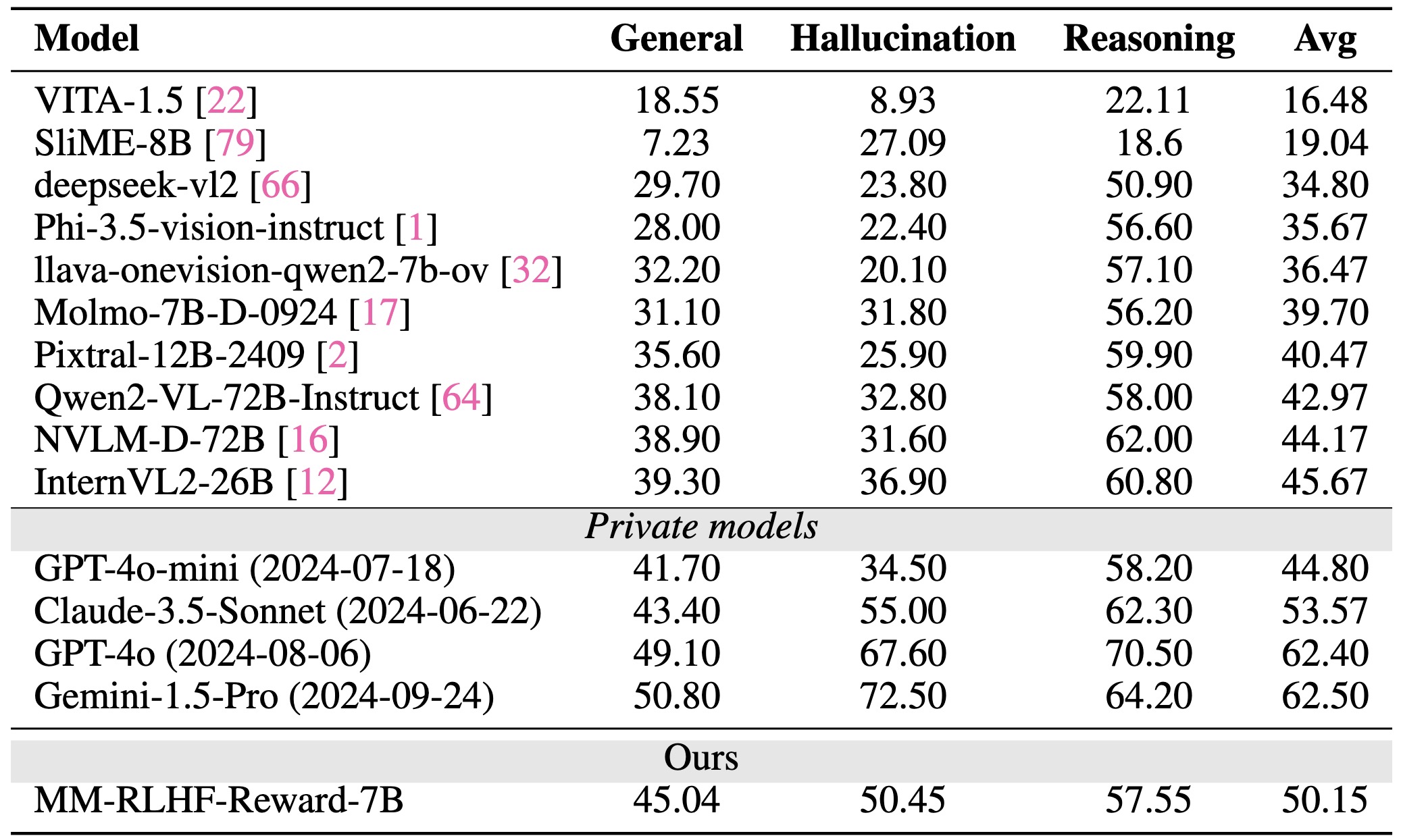
Performance comparison of our reward model (MM-RLHF-Reward) with existing open-source and private MLLMs. MM-RLHF-Reward-7B outperforms existing 72B open-source MLLMs and several competitive closed-source models.
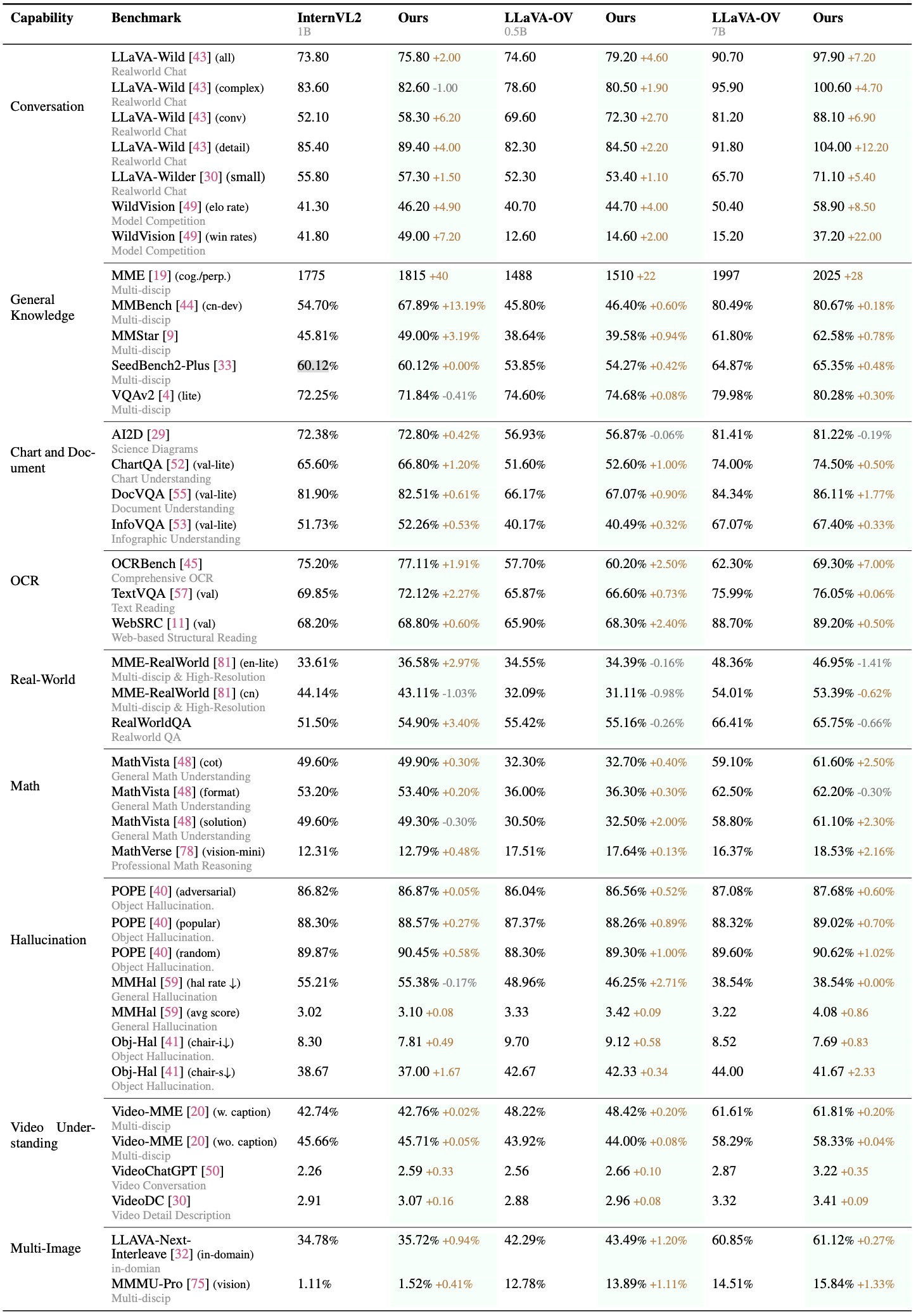
Performance variations after alignment across 8 different evaluation dimensions, comparing multiple models under our alignment strategy. All models show comprehensive performance improvements under the proposed alignment, demonstrating significant gains across various tasks.
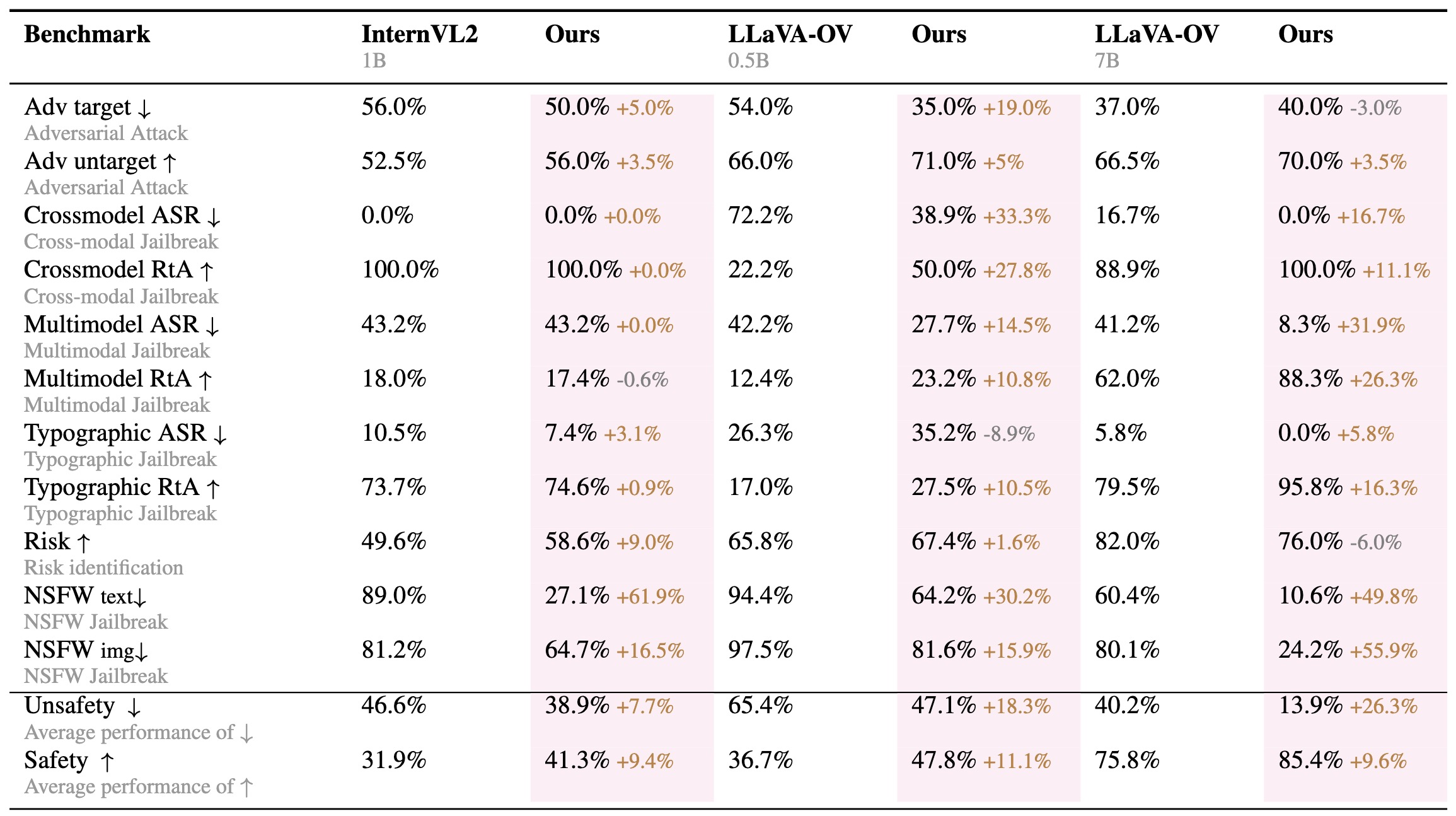
Performance variations after alignment across MM-rlhf-SafeBench, comparing multiple models under our alignment strategy.
@article{zhang2025mmrlhfstepforwardmultimodal,,
title={MM-RLHF: The Next Step Forward in Multimodal LLM Alignment},
author={Yi-Fan Zhang and Tao Yu and Haochen Tian and Chaoyou Fu and Peiyan Li and Jianshu Zeng and Wulin Xie and Yang Shi and Huanyu Zhang and Junkang Wu and Xue Wang and Yibo Hu and Bin Wen and Fan Yang and Zhang Zhang and Tingting Gao and Di Zhang and Liang Wang and Rong Jin and Tieniu Tan},
journal={arXiv preprint arXiv:2502.10391},
year={2025}
}